Web Application
Cross-Media Recommendations
MediaMatch
A website for getting recommendations across movies, TV, and books in one place. Users log items they’ve watched or read, rate them, and browse a feed with a personal “For You” rail and a community “People Love” rail. The catalog supports semantic and keyword search, and a chatbot layer answers taste questions in natural language.
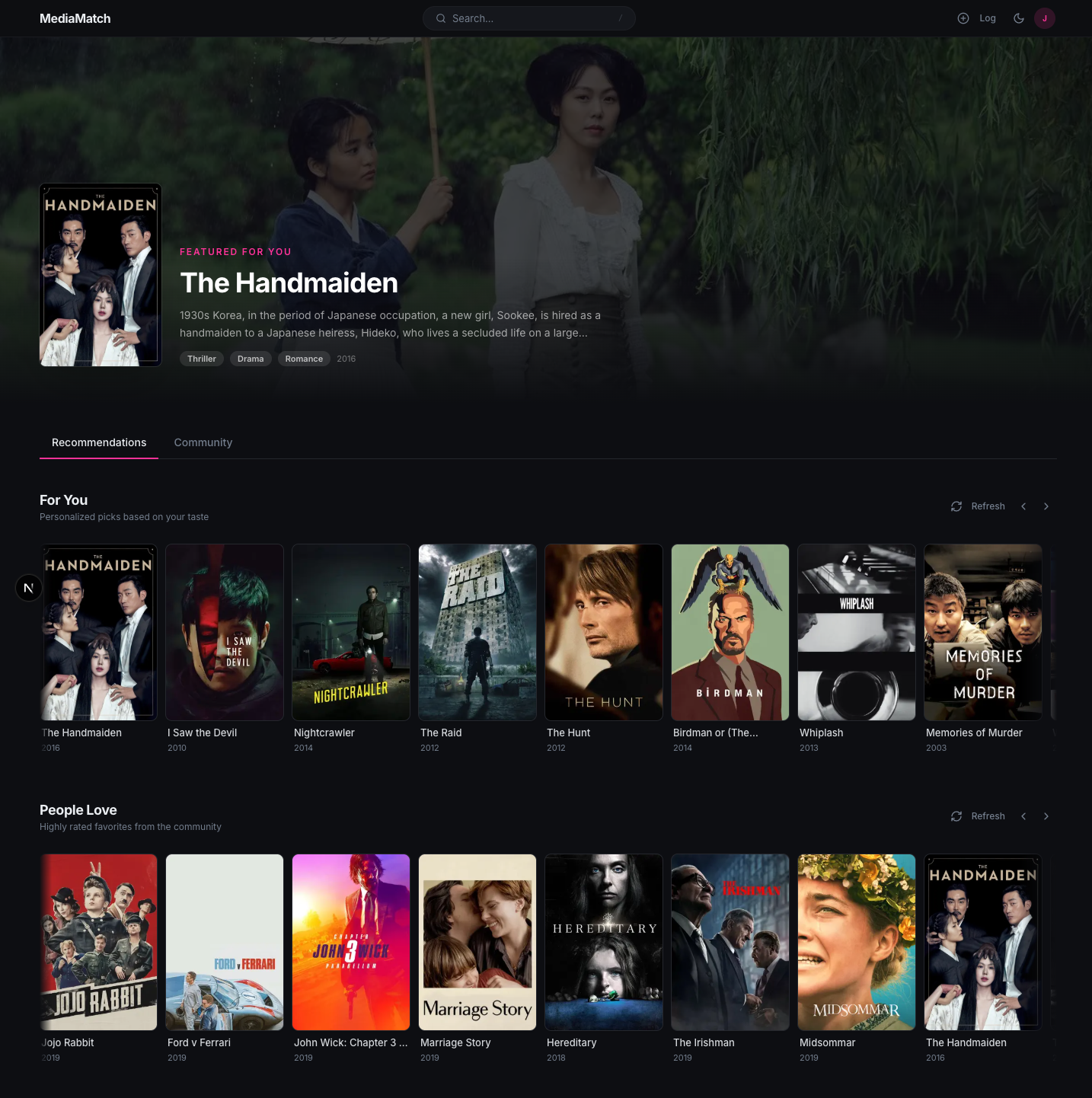
Home feed · scroll to see the full page
What it does
A single feed for movies, TV, and books.
The site covers three media types that are usually split across separate apps. The recommendation engine handles each type with a model appropriate to the data available for it. New users start with a cold-start onboarding grid, then log items, browse a personalized feed, search semantically, and read a Gemini-written taste report.
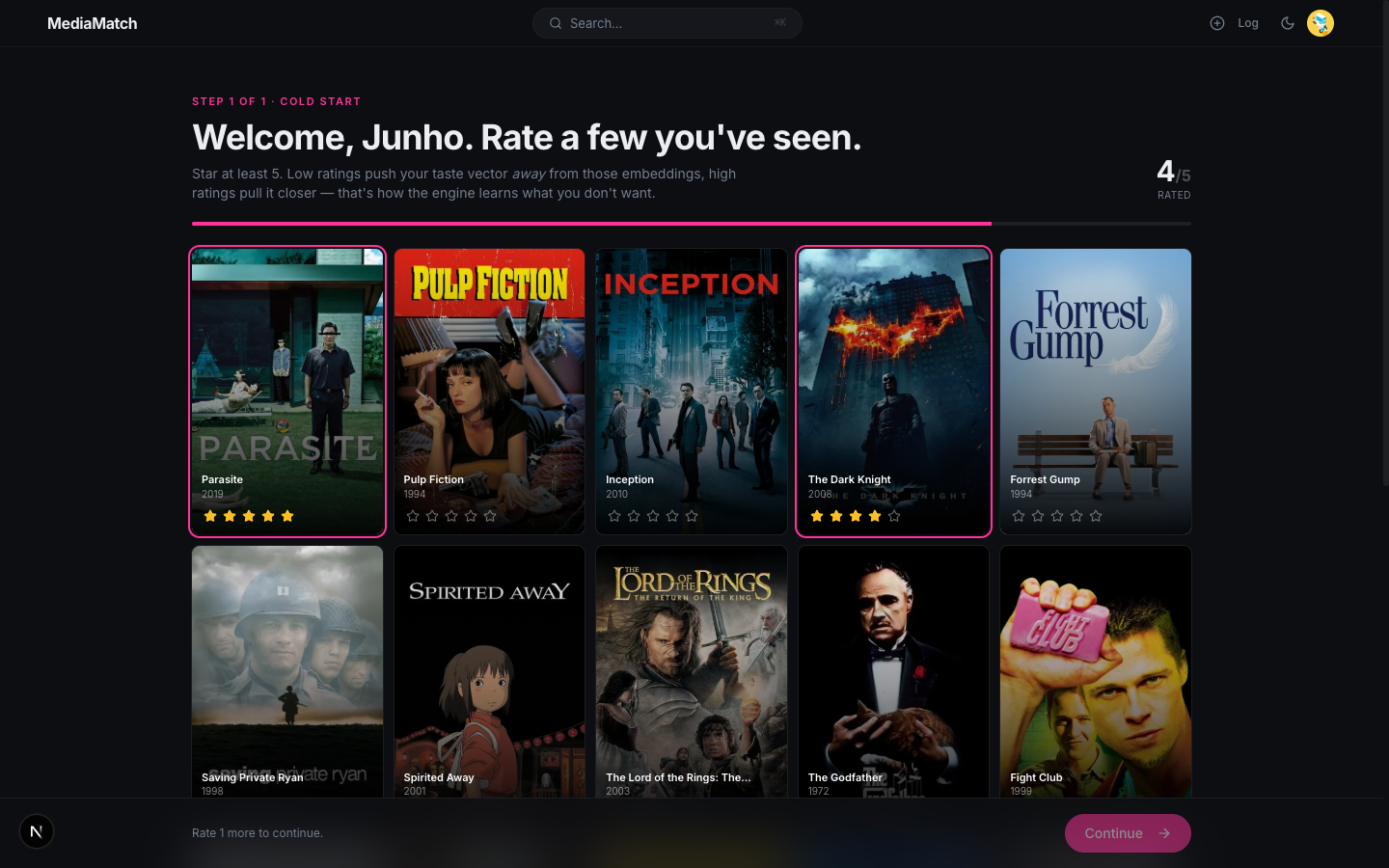
01 · Onboarding
Cold-start rating grid
First-time users land on a grid of forty curated titles (twenty movies, twelve TV shows, eight books, pulled from TMDB and Google Books) and are asked to rate at least five of them. Each rating is written as a normal library entry, so by the time the home feed loads the router already has input for the content-based taste vector and, for any rated movies, the SVD user projection.
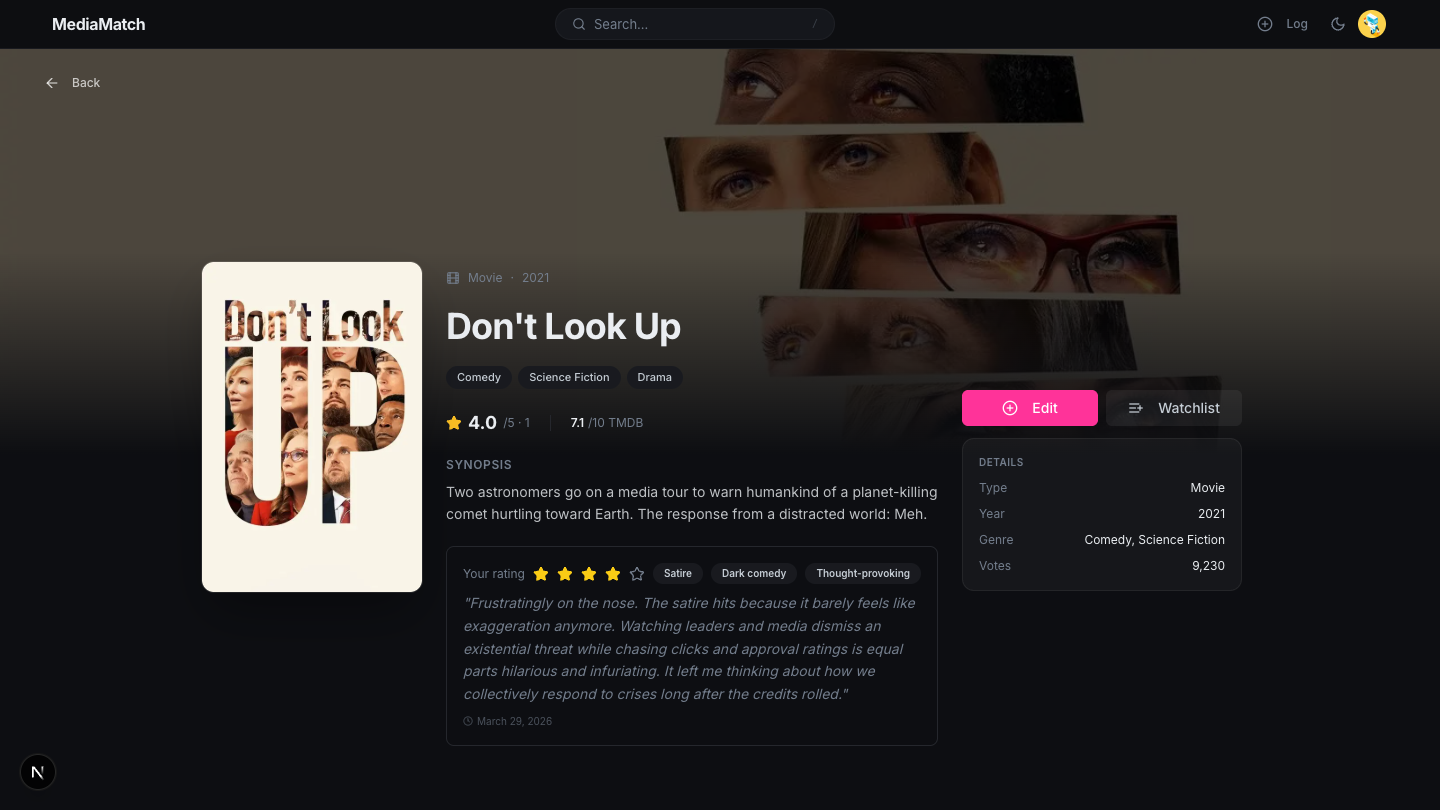
02 · Media detail
Three-column detail page
Each item has a three-column detail page with a poster, a title block with metadata and the user’s logged rating, and a sidebar containing Log/Edit and Watchlist actions plus a Details card (type, year, genre, votes). Backdrops come from TMDB for movies and TV and fall back to a blurred poster for books. A theme-aware --backdrop-brightness variable adjusts backdrop contrast for light and dark mode.
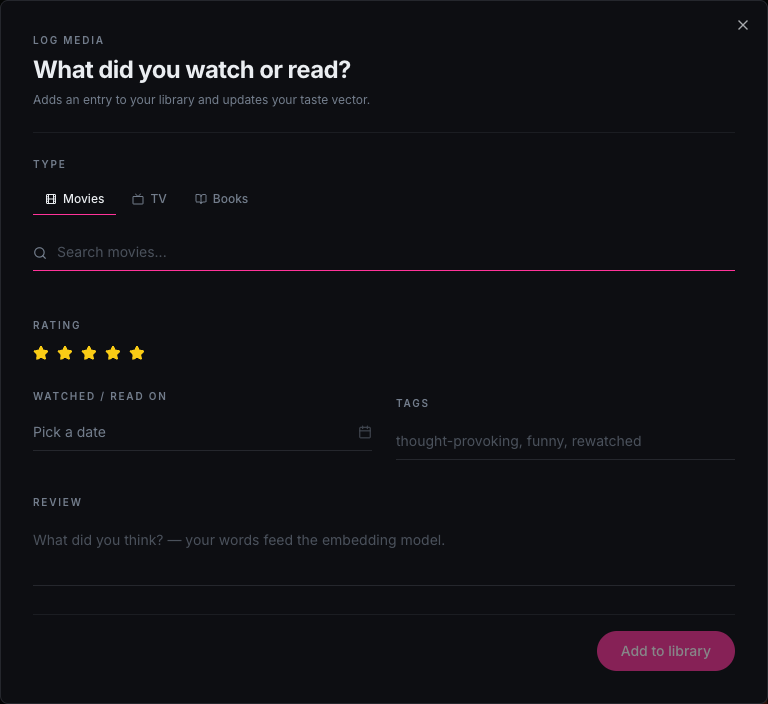
03 · Supporting surfaces
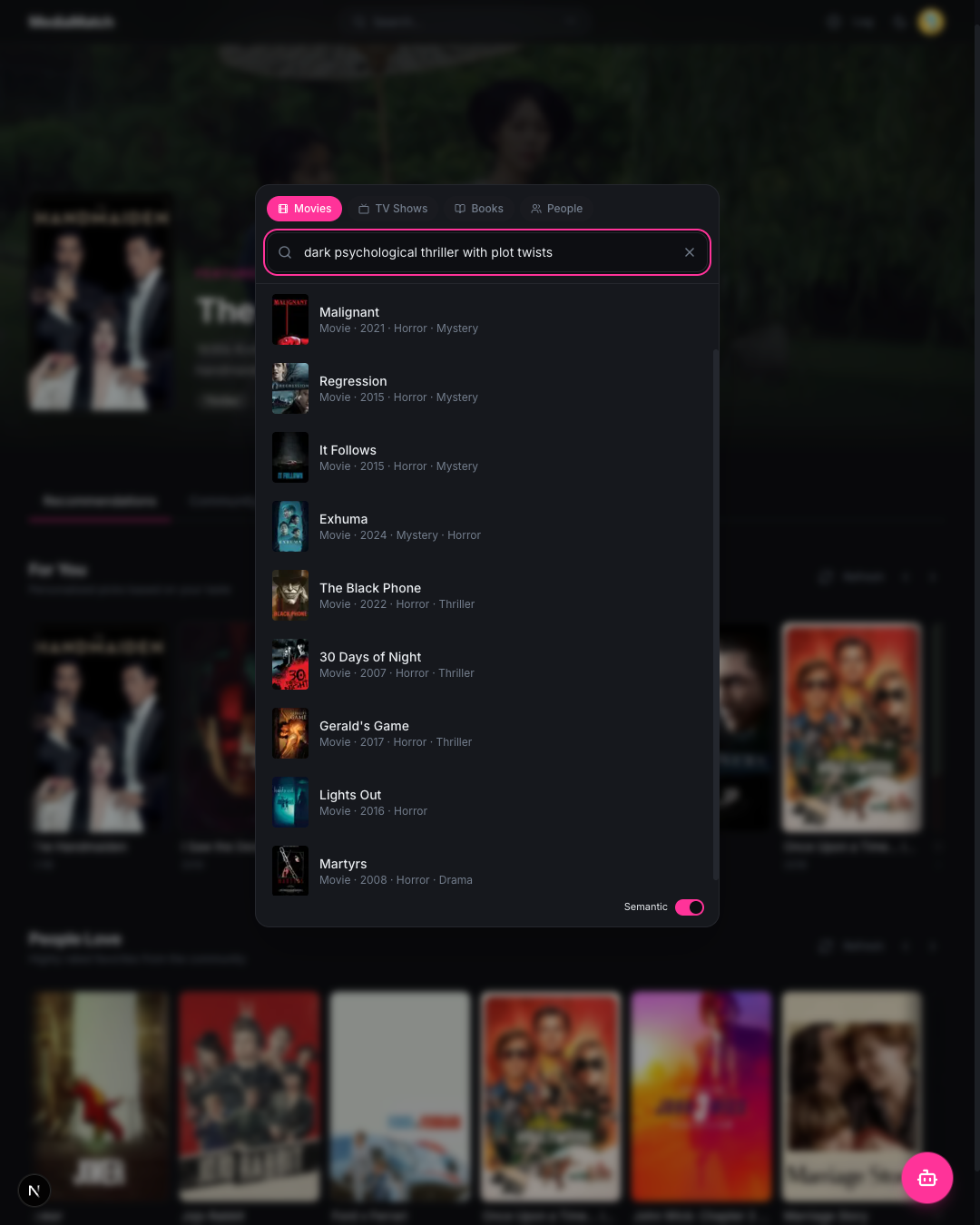
Log, search, chat
Three smaller surfaces fill in around the main feed. A log form searches TMDB and Google Books and captures rating, review, tags, and date in one submit. A Cmd+K overlay runs keyword search by default, with a toggle that switches to semantic search over the embedding index. A floating chatbot sends the user’s library along with each message to Gemini, which replies with grounded, conversational recommendations.
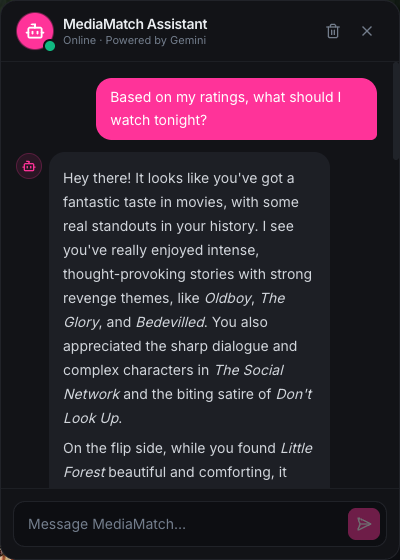
04 · Taste report
Gemini-written library analysis
A dedicated report page sends the user’s logged library — titles, ratings, tags, reviews, genre breakdown, media-type balance — to Gemini and parses the returned JSON into a structured analysis. Reports are cached in Firestore by a signature over the library (entry count plus the latest updatedAt), so the report only regenerates when the library actually changes.
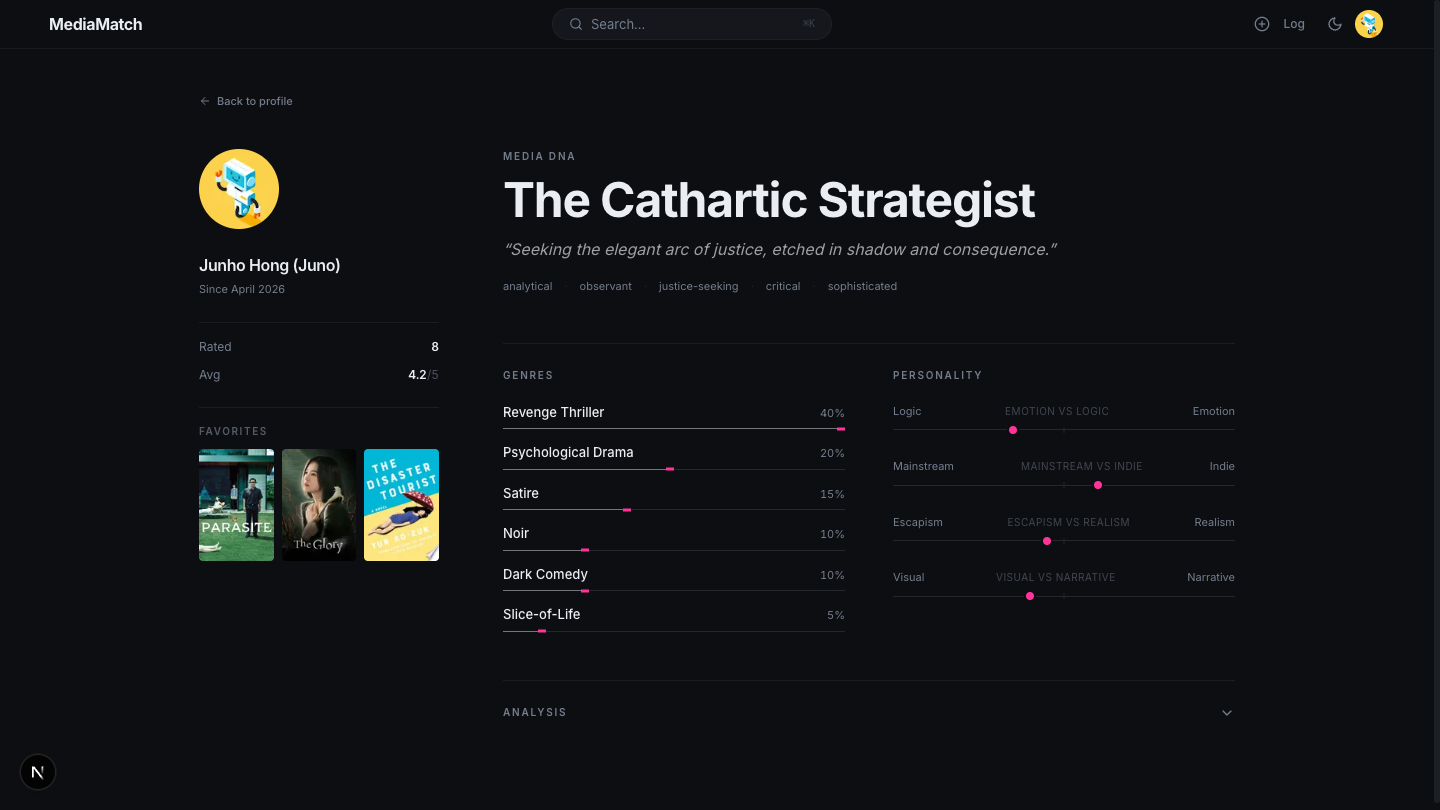
The full profile page
Everything above lives on one profile page: library list, taste summary, media calendar, activity sidebar, and a link to the full taste report.
Architecture
Next.js web app with a Python recommendation service.
The Next.js app handles authentication, CRUD, the UI, and metadata enrichment. Work involving embeddings, rating matrices, and similarity search is handled by a FastAPI service backed by Qdrant. Placing the recommendation layer in Python gives it direct access to sentence-transformers, scikit-learn, scipy, and MLflow.

The Engine
Smart router over two recommendation pipelines
The router picks between two pipelines based on intent: SVD plus content-based for the “For You” rail, and item-item CF plus quality gating for “People Love.” CF is excluded from “For You” because its popularity bias works against personalization. The router loads the movie SVD (trained on MovieLens 25M) and the movie CF model; books and TV always fall through to content-based in the “For You” path, and “People Love” relies on the movie CF model for its community signal. A book CF model is trained on the Goodreads matrix and reachable through the dedicated /recommendations/collaborative endpoint. A book SVD model is also trained but is not currently exposed through any endpoint; the hybrid endpoint loads only the movie SVD.

ml-service/models/router.py — recommend_for_you (simplified)
W_CONTENT, W_SVD = 0.3, 1.0 # base weights, normalized per item
def recommend_for_you(self, rated_items, top_k=20, media_type=None):
if not rated_items:
return self._popular_cold_start(top_k, media_type, set())
cb_scores = self._get_content_scores(rated_items) # all types
svd_scores = self._get_svd_scores(rated_items) # movies only
results = []
for mid in set(cb_scores) | set(svd_scores):
cb = cb_scores.get(mid, 0.0)
svd = svd_scores.get(mid, 0.0)
w_cb = W_CONTENT
w_svd = W_SVD if mid in self.svd.item_mapping and svd != 0 else 0.0
total = w_cb + w_svd
w_cb, w_svd = w_cb / total, w_svd / total # 0.23 / 0.77 when SVD fires
svd_norm = (svd + 1) / 2 if svd != 0 else 0 # map [-1,1] -> [0,1]
results.append({"media_id": mid, "score": w_cb * cb + w_svd * svd_norm})
results.sort(key=lambda r: r["score"], reverse=True)
return results[:top_k]
Models
How each of the three models actually works
The router draws on three underlying models, routed into two pipelines: the movie SVD and content-based combine for “For You,” while the movie item-item CF backs “People Love” behind quality gates. Each model operates on different inputs and produces scores in a different way.

Content-based works for every item type because it only needs the item’s description. It is the only model the router applies to TV and books, and it is what backfills any movie that is not in the MovieLens matrix or any item created on the fly at log time.
SVD requires a user-item rating matrix. The movie model is trained on MovieLens 25M with 100 latent factors and covers the 3,172 catalog movies (out of 4,146) that match a MovieLens title. A second 50-factor model is trained on Goodreads ratings for the 1,390 books that match a Goodreads title, but the router only loads the movie model and the book model is not currently exposed through any endpoint. When the movie SVD fires for a candidate, the router weights it at 0.77 against 0.23 content-based.
Item-item CF has a popularity bias because items with many ratings naturally correlate with many others. The router uses this as a feature rather than a bug and routes CF to the “People Love” rail only, behind per-type quality thresholds. The router loads the movie CF model; a book CF model is trained on the Goodreads matrix and exposed through the dedicated collaborative endpoint, but is not wired into the router.
Offline Evaluation
Four models, measured on held-out ratings
Evaluation runs on up to 200 MovieLens users with at least 20 catalog ratings each. 20% of each user’s ratings are held out, the remaining 80% is fed to each model, and the model’s top-10 is scored against the held-out set (ratings of 4 or higher count as relevant). SVD produces the highest Precision@10 and NDCG@10, but only applies to items with rating history. The router uses it for movies with MovieLens signal and falls back to content-based scoring otherwise.
| Model | Approach | P@10 | NDCG@10 | Routed To |
|---|---|---|---|---|
| Content-based | MiniLM embeddings, cosine sim in Qdrant | 0.015 | 0.017 | Cold-start, TV, new items |
| Item-item CF | MovieLens + Goodreads cosine on sparse matrices | 0.016 | 0.014 | “People Love” rail |
| SVD | TruncatedSVD, 100 factors (movies) + 50 (books) | 0.090 | 0.130 | Items w/ rating signal |
| Hybrid (GBM) | GradientBoosting over [cf, svd, media_type, has_cf] | 0.049 | 0.055 | Not routed — evaluation baseline |
Tracked with MLflow.
Under the Hood
Notable design decisions
01
Mean-centered taste vectors
Each user’s taste vector is a weighted sum of their rated items’ embeddings, then L2-normalized. The weight on each item is its rating minus the user’s mean rating, so items rated above average pull the vector toward them and items rated below average push it away. A low rating contributes a negative signal instead of a small positive one.
02
Review-blended item vectors
When a user writes a review longer than 20 characters, the review text is embedded and blended into the item’s catalog vector via exponential moving average with alpha 0.1. After about ten reviews, the original description contributes roughly 35% of the final vector. No retraining job is required.
03
On-the-fly embedding
Items a user logs that are not already in the catalog are embedded at log time and inserted into Qdrant immediately. This keeps long-tail content available for semantic search and similarity queries as soon as it is added.
04
Anchored weighted sampling
The router fetches five times the requested number of candidates, keeps the top three as fixed anchors, and samples the rest with weights proportional to score squared. The result is stable top picks with some variation in the remainder on each refresh.
05
Two-tier caching
The media collection in Firestore is a write-through cache over TMDB and Google Books, so each item is fetched from an external API only once. Per-user recommendations are cached server-side for one hour and also kept warm on the client so the feed doesn’t reshuffle on every refresh.
06
Quality gates by media type
The “People Love” rail applies different thresholds per type before scoring. Movies require an average rating of at least 7.0 with 100 or more ratings, TV requires the same rating with 50 or more, and books require 3.5 with 10 or more. The thresholds account for differences in dataset size across types.
ML Service API
FastAPI endpoints
The Next.js app communicates with the recommendation service through eight FastAPI endpoints covering recommendations, similarity, search, and embedding updates.
| POST | /recommendations/smart | Main router entry. Returns recs for a given intent + rated items. |
| POST | /recommendations/content-based | Pure content scoring from taste vector. Used for TV, books, cold-start. |
| POST | /recommendations/collaborative | Item-item CF. Backs the “People Love” rail. |
| POST | /recommendations/hybrid | GradientBoosting blend. Used for evaluation comparisons. |
| GET | /similar/{media_id} | k-NN in Qdrant. Backs the detail-page “similar items” section. |
| POST | /search | Semantic search. Embeds query text, filters by media_type if given. |
| POST | /items/embed | On-the-fly embed for a newly logged item not in the catalog. |
| POST | /items/update-embedding | EMA blend of a review vector into an item’s catalog vector. |
Catalog Sources
| TMDB | 7,139 items | Movies, TV, backdrops, reviews |
| Google Books | 3,498 books | Metadata, covers, descriptions |
| MovieLens 25M | 162K users | CF + SVD training |
| Goodreads (UCSD) | 518K users | Book CF training |
| TMDB Reviews | 3,796 items | Embedding enrichment |
| Goodreads Reviews | 1,784 items | Embedding enrichment |
Tech Stack
| Frontend | Next.js 15 (App Router) |
| Tailwind CSS + shadcn/ui | |
| next-themes (light/dark) | |
| Auth & DB | Firebase Auth |
| Cloud Firestore | |
| ML Service | FastAPI |
| sentence-transformers (MiniLM-L6) | |
| scikit-learn (TruncatedSVD, GBM) | |
| Vector DB | Qdrant |
| Tracking | MLflow |
| LLM | Google Gemini (chatbot + taste reports) |