Summary
Three transformer architectures are compared for classifying musical genre from song lyrics alone: RoBERTa-base (encoder-only), GPT-2 (decoder-only), and T5-small (encoder-decoder). All three are fine-tuned with LoRA under matched adapter budgets on a balanced five-genre dataset of roughly 10,000 songs.
The fine-tuned models plateau between F1 0.46 and 0.61. A zero-shot Claude Opus baseline reaches 0.636. A four-part interpretability analysis examines whether this plateau is model-driven or task-driven and locates the ceiling in the data: Pop, Rock, and R&B are distinguished primarily by musical properties that are absent from the text.
Dataset
Songs are drawn from the Genius lyrics corpus on Hugging Face (2.76M songs with genre metadata). The preprocessing pipeline retains English-only songs by requiring agreement between CLD3 and fastText language detectors, strips structural annotations such as [Verse] and [Chorus], and truncates to 2,000 characters. Five genres are retained: Rap, Pop, Rock, Country, and R&B.
Stratified sampling draws 2,000 songs per genre for the architecture comparison, with 2,500 for Pop to offset higher label noise observed during exploratory analysis. A larger 5,000-per-genre sample is used to train the RoBERTa variant used for interpretability. Splits are 80/10/10 with validation and test sets balanced to equal counts per class. All sampling uses a fixed seed.
Setup
All three models are fine-tuned with LoRA (rank 16, α=32, dropout 0.1). Adapter parameters are matched at 590K across models so that the comparison isolates architectural differences rather than adapter capacity. Total trainable parameters still differ because of classification head design, which is documented in the results and treated as a confound rather than an architectural advantage.
Training uses AdamW with a cosine learning rate schedule and 10% linear warmup, max sequence length 512, batch size 64, learning rate 2×10-4, weight decay 0.01, gradient clipping at 1.0, and early stopping on validation macro F1 with patience 3. For RoBERTa the classification head sits on the [CLS] token; for GPT-2 it uses the last non-padding token; T5 is trained in text-to-text mode with greedy decoding and label mapping.
Architecture Comparison
| Model | Trainable | Accuracy | F1 Macro |
|---|---|---|---|
| RoBERTa-base | 1.18M | 0.613 | 0.611 |
| GPT-2 | 0.59M | 0.604 | 0.591 |
| T5-small | 0.59M | 0.454 | 0.463 |
| Claude Opus (zero-shot) | — | 0.649 | 0.636 |
| Random baseline | — | 0.200 | 0.200 |
RoBERTa achieves the highest macro F1 among fine-tuned models (0.611), followed by GPT-2 (0.591) and T5 (0.463). The ranking reflects the full experimental setup and contains two confounds that complicate a purely architectural reading.
First, RoBERTa’s 2-point advantage over GPT-2 coincides with a 150× larger trainable classification head (594K vs 3,800). Some fraction of the gap is attributable to task-specific head capacity rather than bidirectional attention. Second, T5’s larger gap has at least three contributing factors: a smaller base model (60M vs 125M), a text-to-text formulation that introduces decoding overhead for a closed-label task, and the absence of a separate trainable head. A fair architectural comparison would equalize base model size and head design; this study does not.
The cleaner observation is that all three fine-tuned approaches, together with two zero-shot LLM baselines, cluster in a narrow 0.46–0.64 F1 band well below perfect accuracy. Whether this reflects a model ceiling or a task ceiling is not answerable from the comparison alone.
Interpretability Analysis
The plateau raises a question the comparison cannot settle: is the ceiling a property of the models (capacity, optimization, architecture) or a property of the task (the lyrics do not contain enough signal to separate the genres)?
Four analyses are used to constrain the answer. Each is designed to probe a different aspect of the problem so that consistency across them is informative. All four are run on a RoBERTa variant trained on the larger 5,000-per-genre dataset.
Genre centroid similarity (Sentence-BERT)
Songs are encoded with an off-the-shelf sentence encoder (all-MiniLM-L6-v2) that has never seen the task labels. Pairwise centroid cosine similarities quantify task difficulty independently of any trained classifier. If genres are linguistically distinct, centroids should separate in this space.
Layer probing
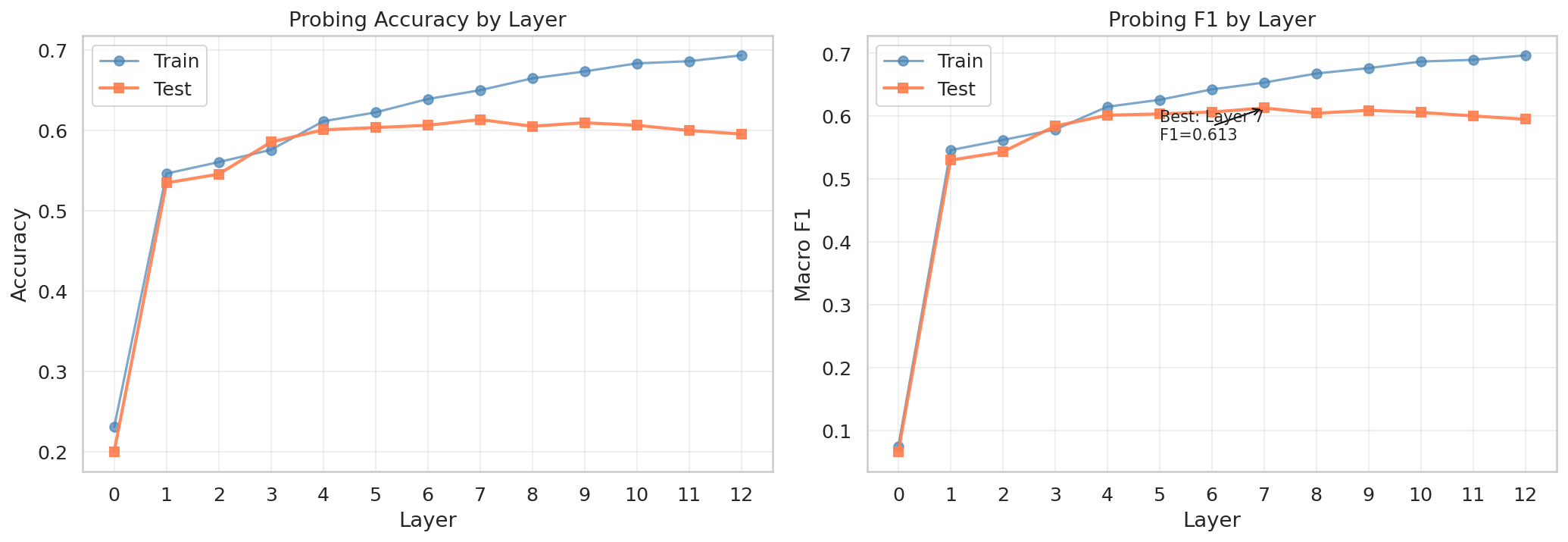
A multinomial logistic regression is fit to the [CLS] embedding at each of RoBERTa’s 13 layers (layer 0 is static embeddings, layers 1–12 are transformer outputs). If depth is contributing useful abstraction, probe F1 should keep improving through the network. A mid-depth plateau would indicate that all linearly accessible signal is already extracted and that additional layers add no further discriminative information.
Representation geometry
Final-layer [CLS] embeddings are projected to 2D with both UMAP and t-SNE (UMAP: k=15, min_dist=0.1; t-SNE: perplexity 30, 1,000 iterations). If the classes are learnable but the classifier is weak, clusters should still be findable. Heavy interleaving would indicate that the representation manifold itself is tangled.
Contrastive Integrated Gradients
For the top confused pairs identified from the confusion matrix, token attributions are computed against the logit difference fA(x) − fB(x) rather than a single target class. Standard IG assigns high scores to tokens shared between the two classes (for example “love” between Pop and Country), which are not discriminative. The contrastive formulation isolates the vocabulary that actually distinguishes A from B, making it a more informative attribution when genres share substantial lexicon. Implemented with Captum, 30 interpolation steps per sample, aggregated across 30 samples per pair.
Results
Genre centroid similarity
Pop–Rock centroids reach cosine similarity 0.979 and Pop–Country 0.974. Rap is the only genre whose centroid is noticeably distinct from the others (0.84–0.88). At the sample level, within-genre and between-genre pairwise similarity distributions overlap almost entirely (means 0.363 and 0.331). In an embedding space that has never seen the labels, most of the genres are not reliably separable.
Layer probing
Probe F1 climbs from 0.067 at layer 0 (static embeddings, effectively chance) to 0.530 at layer 1, improves steadily through 0.613 at layer 7, then flattens. The final layer comes in at 0.595, slightly below the peak. Additional depth beyond layer 7 does not add linearly accessible genre information.
Representation geometry
UMAP and t-SNE projections of the final-layer [CLS] embeddings agree. Rap forms a tight, well-separated cluster, consistent with its distinctive vocabulary. Country clusters reasonably well. Pop, Rock, and R&B are heavily interleaved in both projections. The cluster structure matches the similarity analysis: the classes that are close in the independent Sentence-BERT space are also tangled in the trained model’s representation space.
Contrastive Integrated Gradients
For Rock versus Pop, the tokens with highest contrastive attribution toward Rock are intensity terms (death, blood, pain); toward Pop, they are light-emotional terms (love, night, feel). For Country versus Pop, rural and domestic terms (truck, town, mama) push toward Country. Misclassified examples systematically violate these patterns, for instance a Rock song using light-emotional vocabulary. The attributions are consistent with the model having learned reasonable genre-discriminating features and failing on songs that are genuinely ambiguous at the lexical level.
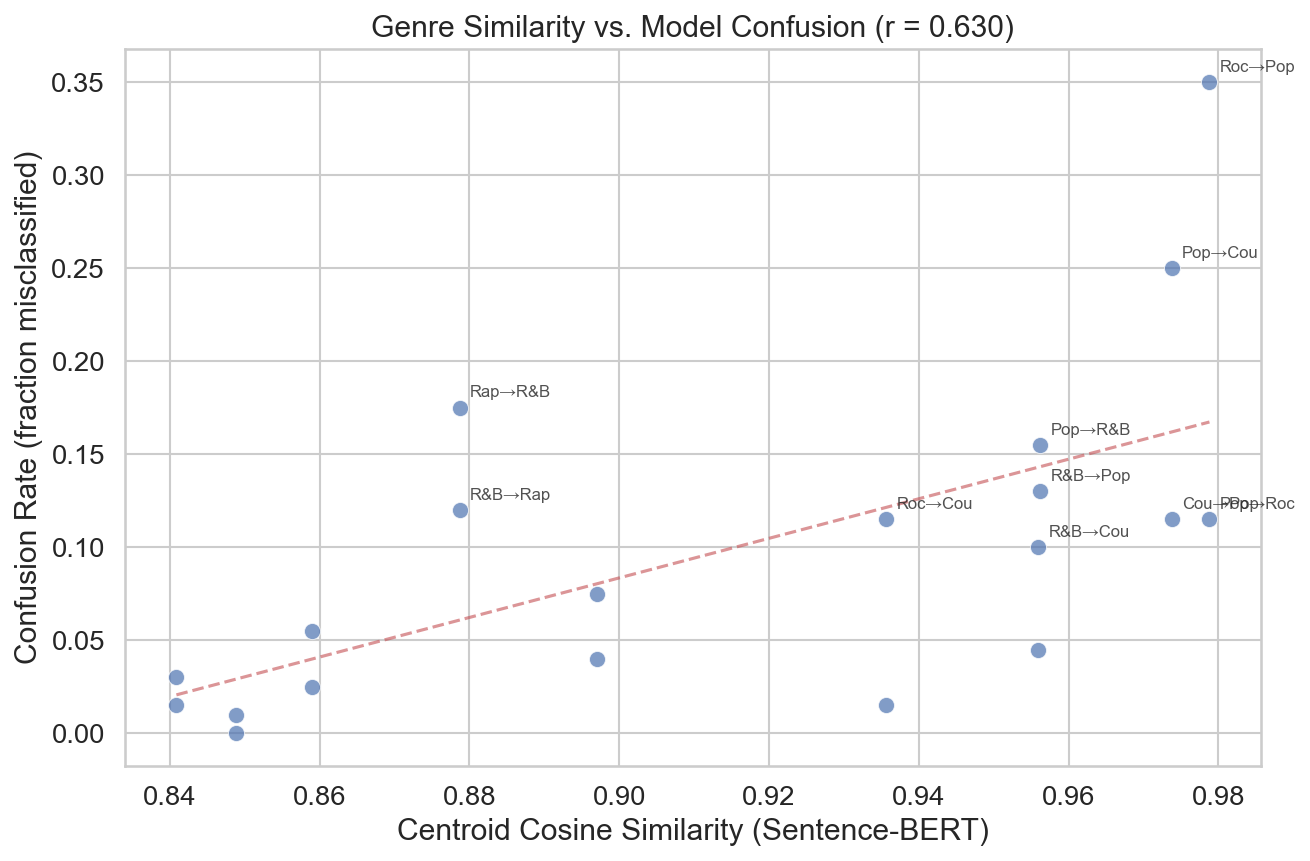
Error–similarity correlation
Across the 20 directed genre pairs, RoBERTa’s per-pair confusion rate and the corresponding Sentence-BERT centroid similarity correlate at Pearson r = 0.630. The three highest confusion rates are Rock→Pop (35%, similarity 0.979), Pop→Country (25%, 0.974), and Rap→R&B (17.5%, 0.879). Rap→Country, with the lowest similarity (0.849), has 0% confusion.
Performance Ceiling
The four analyses produce consistent results: genres are heavily overlapping in an independent embedding space, the classifier saturates at mid-depth, learned representations reproduce the expected cluster structure, and classification errors track the underlying similarity structure of the data. Together they are consistent with a task-level ceiling on lyrics-only five-genre classification at roughly F1 0.65.
A zero-shot Claude Opus baseline reaches F1 0.636, providing an additional reference point from a model with world knowledge about artists and musical context that the fine-tuned models do not have. The 2.5-point gap to the fine-tuned RoBERTa (0.611) is small given the difference in scale and prior knowledge.
The ceiling is not specific to any particular architecture or size: it holds from T5-small (60M) through fine-tuned RoBERTa-base (125M) to a frontier LLM in zero-shot. Pop, Rock, and R&B are distinguished primarily by non-lyrical properties: instrumentation, tempo, production, vocal timbre. Exceeding this bound on the same taxonomy requires multimodal inputs rather than larger text-only models.
Limitations
All reported numbers are single-seed point estimates; multi-seed variance is not reported, and the 2-point gap between RoBERTa and GPT-2 may be within noise. The comparison is not head-normalized or base-size-normalized. The Genius dataset contains label noise, particularly for Pop. The 2,000-character truncation disproportionately affects Rap, whose median length is at the cap. The five-genre taxonomy is coarse, and finer-grained or hierarchical labels could produce different conclusions. LLM baselines use a 250-song subset (50 per genre), and their per-class F1 has higher variance than the full test set.
Method Notes
Comparison dataset: 2,000 songs per genre (2,500 for Pop), ~8,000 train / 1,000 val / 1,000 test. Interpretability dataset: 5,000 songs per genre (6,000 for Pop). LoRA: rank 16, α=32, dropout 0.1, adapter budget 590K. Targets: query/value for RoBERTa, c_attn for GPT-2, query/value in encoder and decoder for T5. Optimizer: AdamW with cosine schedule, 10% warmup. Max length 512, batch 64, LR 2×10-4, weight decay 0.01, gradient clip 1.0, early stopping patience 3 on val macro F1. Interpretability RoBERTa uses expanded LoRA targets (query/key/value), LR 1×10-4, gradient accumulation for effective batch 64, FP16, and random contiguous word cropping as augmentation; its test F1 (0.608) matches the comparison RoBERTa (0.611). Sentence-BERT model: all-MiniLM-L6-v2. Integrated Gradients via Captum, 30 interpolation steps. LLM baselines evaluated on 50 songs per genre with a system prompt constraining output to a single genre label; treated as illustrative.